Python一键下载视频脚本分享
需求
小编通常会上一些专业的视频网站比如腾讯视频、优酷,在上面看电影、电视剧。这些网站有个优点,可以缓存视频,在通勤路上比如地铁就可以愉快的刷剧了,因为地铁上的网速通常不怎么好。
但是有一些经典电影或者电视剧,这些视频并没有提供,那么我们只能上一些小电影网站看了,资源是有了,但是问题来了,这些小电影网站大多数都没有视频下载功能,那在地铁上就没法看了。
如果可以把这些视频下载下来,再传输到手机里不就可以离线看了吗?
接下来小编就演示下如何用 python 脚本来实现一键下载小电影网站的视频。
以下脚本可以学习到
- python selenium 的使用
- python requests 的使用
- 分片下载视频存储本地
- 实时输出视频下载进度
注意:
这里的脚本主要用于测试学习目的,切勿用于生产环境等商业目的
推荐大家访问官方指定平台或专业视频网站,支持正版
解决方案
小编以经常看的在线之家为例,这个网站可以找到很多美剧资源。
首先,我们用谷歌浏览器打开一个视频地址,比如https://www.zxzj.fun/video/1529-1-1.html,按F12或者右击“检查”打开浏览器控制台
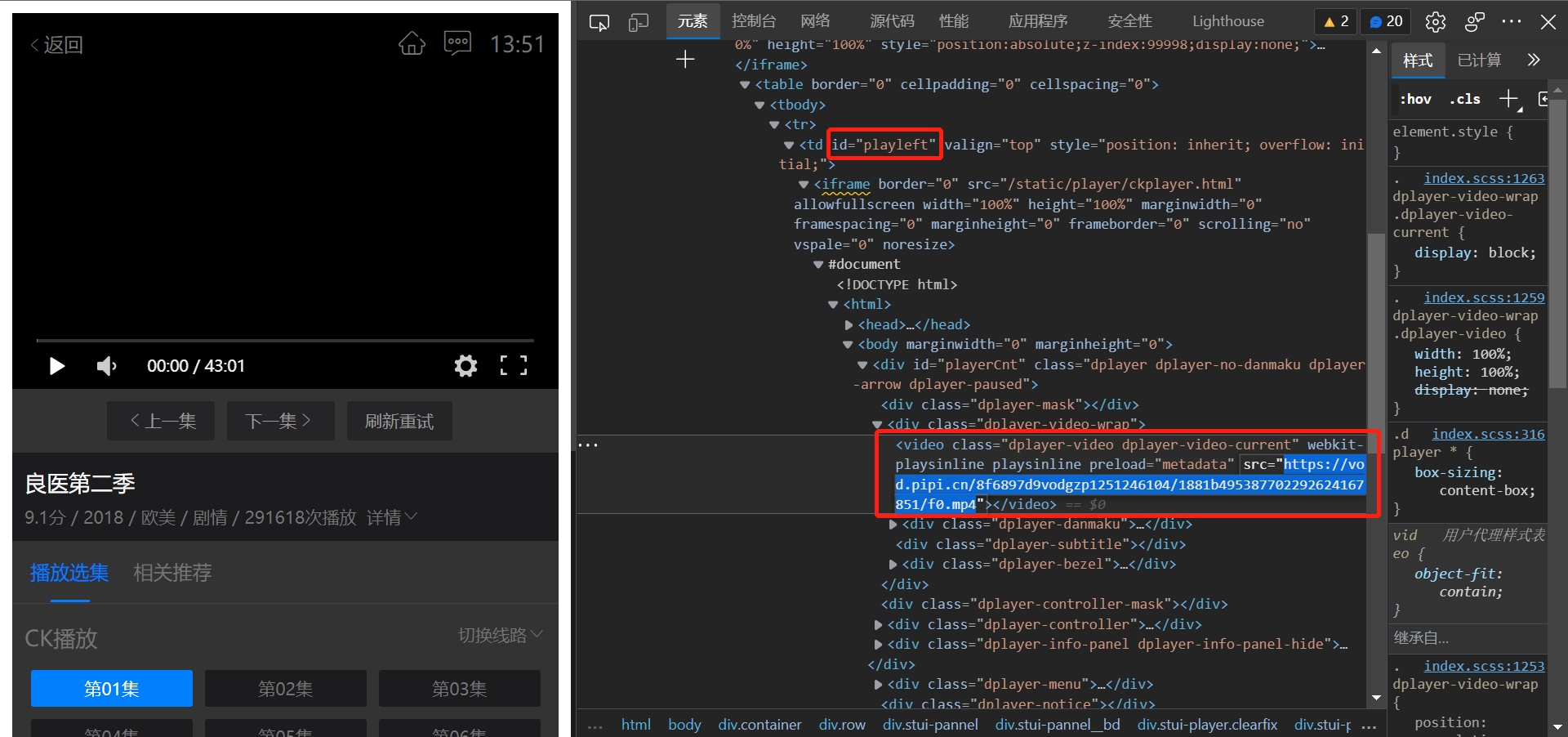
然后,点击控制台最左边的选择元素按钮,或者按Ctrl + Shift + C,选择网页的视频区域,就能看到video标签
<video
class="dplayer-video dplayer-video-current"
webkit-playsinline=""
playsinline=""
preload="metadata"
src="https://vod.pipi.cn/8f6897d9vodgzp1251246104/1881b495387702292624167851/f0.mp4"
></video>
可以发现src属性值就是视频链接,并且是采用单独的.mp4视频地址,这种地址原理上可以直接从浏览器下载的,直接复制这个地址在浏览器打开,就可以右击下载。但是电视剧通常有很多集,每次都手动打开网页-打开控制台-复制视频地址-再打开视频-最后下载视频,就很繁琐。这时候就是脚本排上用场的时候了,可以把这个流程自动化,简化重复操作的过程。
脚本的整体思路
- 使用
selenium打开网页 - 通过
selenium元素选择器找到video标签所在的iframe,切换到iframe - 通过
video标签,获取到视频地址,然后请求视频内容 - 采用分片下载的方式拼接视频存储到本地
代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
# 谷歌浏览器驱动
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# sleep模块,让程序停止往下运行
from time import sleep
# 设置谷歌浏览器驱动
driver = webdriver.Chrome()
# 手动改为想要下载的视频所在网页地址
url = 'https://www.zxzj.fun/video/1529-1-1.html'
# 打开网页
driver.get(url)
try:
# 通过元素选择器找到iframe
iframe = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.CSS_SELECTOR, '#playleft iframe'))
)
except:
driver.quit()
# 获取到网页title,便于直观看到当前下载的视频标题
title = driver.find_elements(By.TAG_NAME, 'title')[
0].get_attribute('innerHTML')
# 切换到iframe
driver.switch_to.frame(iframe)
# 通过video标签获取视频地址
video = driver.find_elements(By.TAG_NAME, 'video')[0]
video_url = video.get_attribute('src')
print('video', video_url)
# 已经获取到视频地址,可以关闭浏览器
driver.quit()
# 设置请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'
}
# 请求视频内容
video_content = requests.get(video_url, headers=headers, stream=True)
print("开始下载")
# 视频大小
contentLength = int(video_content.headers['content-length'])
line = '大小: %.2fMB'
# 大小换算
line = line % (contentLength/1024/1024)
# 打印视频总长度
print(line)
# 存储已经下载的长度
downSize = 0
print('video_name', title)
# 分片下载
with open(title+'.mp4', "wb") as mp4:
for chunk in video_content.iter_content(chunk_size=1024 * 1024):
if chunk:
mp4.write(chunk)
# 记录已下载视频长度,实时输出下载进度
downSize += len(chunk)
print('进度:{:.2%}'.format(downSize / contentLength), end='\r')
print("下载结束")
总结
以上简单展示了使用 python 的requests、selenium库来下载一个mp4视频,可以当做一个学习案例。
其中还有很多待改进的地方
- 每次运行脚本只能解析下载一个视频,或许可以改进为批量解析出一个视频列表来下载
- 换视频地址下载,需要手动改源码的
url地址,可以改进做一个界面交互来让用户输入 - 当前只适配了特定网站的视频地址解析,其他地址不支持,可以改进针对不同的网站单独出解析函数来匹配
后续有时间再来分享更多有趣实用的 python 脚本。
评论