Python One-Click Download Video
Question
I usually go to professional video sites such as YouTube video or Netflix to watch movies and TV shows on them. These websites have the advantage of being able to cache videos, so you can enjoy watching movies on commuting roads, such as the subway, because the internet speed on the subway is usually not very good.
But there are some classic movies or TV series, these videos are not provided, so we can only watch some small movie websites, the resources are available, but the problem is that most of these small movie websites do not have video download features. You can't watch it on the subway.
If you can download these videos and transfer them to your phone, can you watch them offline?
Next, the editor will demonstrate how to use a python script to download videos from a small movie website with one click.
We will learn
- How to use python selenium
- How to use python requests
- Fragmented download video storage locally
- Real-time output of video download progress
Note:
The script here is mainly used for testing and learning purposes, and should not be used for commercial purposes such as a production environment
Recommend everyone to visit the official designated platform or professional video website, support genuine
Analysis
The editor takes the frequently-watched zxzj.fun as an example. You can find a lot of media resources on this website.
First, we use Google Chrome to open a video address, such as https://www.zxzj.fun/video/1529-1-1.html, press F12 or right-click "check" to open the browser console
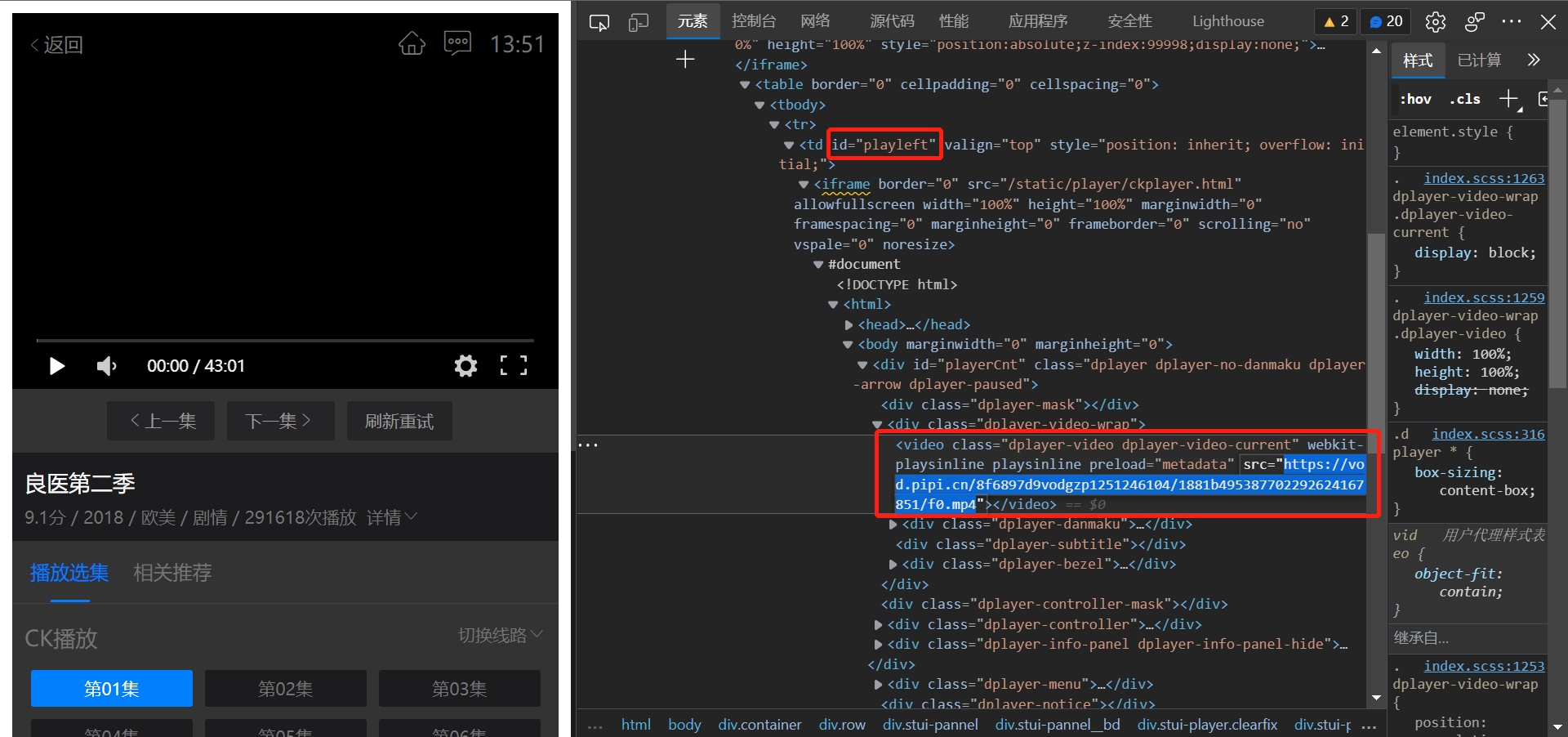
Then, click the select element button on the far left of the console, or press Ctrl + Shift + C, select the video area of the webpage, and you can see the video tag
<video
class="dplayer-video dplayer-video-current"
webkit-playsinline=""
playsinline=""
preload="metadata"
src="https://vod.pipi.cn/8f6897d9vodgzp1251246104/1881b495387702292624167851/f0.mp4"
></video>
It can be found that the src attribute value is the video link, and a separate .mp4 video address is used. In principle, this address can be downloaded directly from the browser. Just copy this address and open it in the browser, and then right-click to download. However, TV series usually have many episodes. It is very cumbersome to manually open the webpage every time - open the console - copy the video address - then open the video - finally download the video. The script should be used at this time. You can automate this process and simplify the process of repeated operations.
The overall idea of the script
- Use
seleniumto open web pages - Use the
seleniumelement selector to find theiframewhere thevideotag is located, and switch to theiframe - Get the video address through the
videotag, and then request the video content - The video is stitched and stored locally by downloading in pieces
Code
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
# Google Chrome Driver
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# sleep module, let the program stop running down
from time import sleep
# Set up Google Chrome driver
driver = webdriver.Chrome()
# Manually change the URL of the webpage where the video you want to download is located
url ='https://www.zxzj.fun/video/1529-1-1.html'
# open the Web page
driver.get(url)
try:
# Find the iframe through the element selector
iframe = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.CSS_SELECTOR,'#playleft iframe'))
)
except:
driver.quit()
# Get the title of the webpage, so that you can visually see the title of the currently downloaded video
title = driver.find_elements(By.TAG_NAME,'title')[
0].get_attribute('innerHTML')
# Switch to iframe
driver.switch_to.frame(iframe)
# Get the video address through the video tag
video = driver.find_elements(By.TAG_NAME,'video')[0]
video_url = video.get_attribute('src')
print('video', video_url)
# The video address has been obtained, you can close the browser
driver.quit()
# Set request header information
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'
}
# Request video content
video_content = requests.get(video_url, headers=headers, stream=True)
print("Start downloading")
# Video size
contentLength = int(video_content.headers['content-length'])
line ='Size: %.2fMB'
# Size conversion
line = line % (contentLength/1024/1024)
# Print the total length of the video
print(line)
# Store the downloaded length
downSize = 0
print('video_name', title)
# Fragmented download
with open(title+'.mp4', "wb") as mp4:
for chunk in video_content.iter_content(chunk_size=1024 * 1024):
if chunk:
mp4.write(chunk)
# Record the length of the downloaded video and output the download progress in real time
downSize += len(chunk)
print('Progress: {:.2%}'.format(downSize / contentLength), end='\r')
print("download end")
Conclusion
The above simply shows the use of python's requests and selenium libraries to download a mp4 video, which can be used as a study case.
There are still many places to be improved
- Each time the script is run, only one video can be parsed and downloaded, maybe it can be improved to batch parse out a list of videos to download
- Change the video address to download, you need to manually change the source code
urladdress, you can improve an interface interaction to allow users to input - Currently only adapted to the video address resolution of a specific website, other addresses are not supported, it can be improved to separate the analysis function for different websites to match
I'll share more interesting and useful python scripts later when I have time.
Comments